

smart_toy
Machine Learning
keyboard_arrow_down 36 guides
1. ML models
Simple linear regressionLogistic regressionk-means clusteringlockHierarchical clusteringlockDBSCANlockNaive bayeslockDecision treeslockk-nearest neighborslockPerceptronslock
2. Feature engineering
Feature scalingLog transformationText vectorizationlockGrid searchlockRandom searchlockPrincipal component analysislock
3. Optimization
4. Model evaluation
check_circle
Mark as learned thumb_up
0
thumb_down
0
chat_bubble_outline
0
Comment auto_stories Bi-column layout
settings
Comprehensive Guide on ReLU
schedule Aug 11, 2023
Last updated local_offer
Tags Machine Learning●Python
tocTable of Contents
expand_more Master the mathematics behind data science with 100+ top-tier guides
Start your free 7-days trial now!
Start your free 7-days trial now!
Rectified linear units, or ReLU, is an activation function that is commonly used for neural networks. The mathematical formula for ReLU is quite simple:
$$f(x)=\max(0,x)$$
This formulation is actually equivalent to the following:
$$f(x)=
\begin{cases}
x&(x\gt0)\\
0&(x\le0)
\end{cases}$$
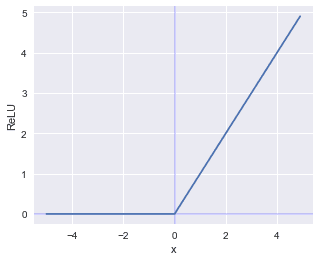
Graphically, ReLU would look like the following:
Implementation in Python
The implementation of ReLU is straight-forward:
import numpy as np
def relu(x): return np.maximum(0,x)
Derivative of ReLU
The derivative of ReLU is straight-forward - we just need to consider the two cases:
when $x$ is less than or equal to zero - the derivative would simply be 0 since the slope is flat
when $x$ is larger than zero - the derivative would be 1 since we just have a linear curve $y=x$.
Mathematically, this is the following:
$$\frac{\partial{y}}{\partial{x}}=
\begin{cases}
1&(x\gt0)\\
0&(x\le0)
\end{cases}$$
Published by Isshin Inada
Edited by 0 others
Did you find this page useful?
thumb_up
thumb_down
Comment
Citation
Ask a question or leave a feedback...
thumb_up
0
thumb_down
0
chat_bubble_outline
0
settings
Enjoy our search
Hit / to insta-search docs and recipes!