

Getting Started with Beautiful Soup
Start your free 7-days trial now!
What is Beautiful Soup?
Beautiful Soup is a Python library that allows you to retrieve desired data from HTML and XML.
Overall flow
Use the
urllib.requestmodule to retrieve the HTML from a website.Pass the HTML to Beautiful Soup to retrieve a
BeautifulSoupobject representing the HTML tree structure.Use methods included in Beautiful Soup to filter the
BeautifulSoupobject, and retrieve only the information you are after.
Installing
To install Beautiful Soup using pip or conda:
pip install beautifulsoup4conda install beautifulsoup4
Importing
To import Beautiful Soup:
from bs4 import BeautifulSoup
Terminology
Different Objects
There are 4 types of objects in Beautiful Soup:
Tag
The term tag is often used interchangeably with element.
In the above example we have a <p> tag: <p>Hello World</p>
NavigableString
The text within a tag.
A NavigableString is similar to a Python string, however, it also supports some features specific to Beautiful Soup. You can convert a NavigableString to a normal Python string using the str(~) method.
BeautifulSoup
A BeautifulSoup object represents the whole parsed document (you can think of it as a collection of all the tags in an HTML document).
It behaves similarly to a Tag, however, unlike a Tag it does not have any attributes.
Comments
A Comment is a special type of NavigableString which is displayed with special formatting.
A comment is indicated by the <!--comment--> syntax.
Other terminology
Name
Every tag has a name which can be accessed using .name:
html = """<p>Hello World</p>"""
soup = BeautifulSoup(html, 'html.parser')tag = soup.ptag.name
'p'
Attributes
A tag can have multiple attributes. For example, the tag <div id="people"> has an attribute "id" with value "people". You can access the value of an attribute using tag["attribute"] syntax.
my_html = """<div id="people"> <div id="profile"> <p>Alex</p> </div></div>"""tag = BeautifulSoup(my_html).divtag["id"]
'people'
Parent
The Tag.parent property returns the parent for the particular tag:
my_html = """<div id="people"> <div id="profile"> <p>Alex</p> </div></div>"""soup = BeautifulSoup(my_html)p_tag = soup.find("p")print(p_tag.parent)
<div id="profile"><p>Alex</p></div>
Notice how the parent tag printed includes the child tag <p>Alex</p>.
Children
The Tag.children property in Beautiful Soup returns a generator used to iterate over the immediate child elements of a Tag. To iterate over children of the <div> tag:
Sibling
Tags that are at the same indentation level are known as siblings. We can navigate between siblings using the .next_sibling and .previous_sibling properties.
Webscraping Workflow
Inspect the Website
Right click on the element to inspect, which lets us look at the HTML code.
Parse HTML
Now we know the structure of the HTML we are trying to retrieve data from, we can start to parse the HTML. We will use Beautiful Soup to parse the page and search for specific elements.
To connect to the website and get the html we will use urllib which is a Python Standard Library.
Url of the website to retrieve data from:
url = "url_we_want_to_retrieve_data_from"
Connect to the website using urllib:
try: page = urllib.request.urlopen(url)except: print("Error")
We next pass the page object to Beautiful Soup:
soup = BeautifulSoup(page, 'html.parser')
A parser in layman's terms is something that will check whether the input belongs to a particular language or not. For example, an HTML parser will check whether the input is valid HTML or not, allowing us to know that we have properly structured HTML data to work with (or not if there are any errors).
Extracting information
Find specific tags
To find the tag we are interested in, we can search in many different ways such as using:
Getting text from the tag
Once we have identified the tag we are interested in, we can use the get_text() method to extract the text within the tag.
To extract the text contained within the <b> tag:
Webscraping Example
Let us say we are interested in extracting the following paragraph from the Python wikipedia pageopen_in_new:

Inspect the website
We can right click the highlighted paragraph and click "Inspect" to understand which tag contains this information we are after:
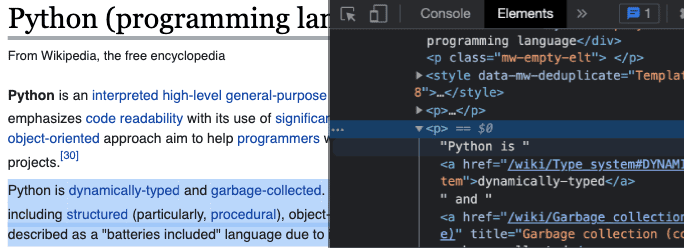
Parse HTML
To connect to the website using urllib and storing the HTML of the page to a BeautifulSoup object:
# Importing required librariesfrom bs4 import BeautifulSoupimport urllib.request
# URL of the page we would like to scrape fromurl = "https://en.wikipedia.org/wiki/Python_(programming_language)"
try: page = urllib.request.urlopen(url)except: # Create a BeautifulSoup object to store the datasoup = BeautifulSoup(page, 'html.parser')
# Print the BeautifulSoup object and check the type of the objectprint(soup)
<!DOCTYPE html><html class="client-nojs" dir="ltr" lang="en"><head><meta charset="utf-8"/><title>Python (programming language) - Wikipedia</title><script>document.documentElement.className="client-js";RLCONF={"wgBreakFrames":!1,"wgSeparatorTransformTable":["",""],"wgDigitTransformTable":["",""],"wgDefaultDateFormat":"dmy","wgMonthNames":["","January","February","March","April","May","June","July","August","September","October","November","December"],"wgRequestId":"a75a29f4-8bc1-435e-b5c0-4e1962eaf0a3","wgCSPNonce":!1,"wgCanonicalNamespace":"","wgCanonicalSpecialPageName":!1,"wgNamespaceNumber":0,"wgPageName":"Python_(programming_language)","wgTitle":"Python (programming language)","wgCurRevisionId":1031165903,"wgRevisionId":1031165903,"wgArticleId":23862,"wgIsArticle":!0,"wgIsRedirect":!1,"wgAction":"view","wgUserName":null,"wgUserGroups":["*"],"wgCategories":["All articles with dead external links","Articles with dead external links from June 2021","Articles with short description","Short description is different from Wikidata","Use dmy dates from August 2020","Articles containing potentially dated statements from March 2021","All articles containing potentially dated statements","Articles containing potentially dated statements from February 2021","Pages using Sister project links with wikidata namespace mismatch","Pages using Sister project links with hidden wikidata","Wikipedia articles with GND identifiers","Wikipedia articles with BNF identifiers","Wikipedia articles with LCCN identifiers","Wikipedia articles with FAST identifiers","Wikipedia articles with MA identifiers","Wikipedia articles with SUDOC identifiers","Articles with example Python (programming language) code","Good articles","Python (programming language)","Class-based programming languages","Computational notebook","Computer science in the Netherlands","Cross-platform free software","Cross-platform software","Dutch inventions","Dynamically typed programming languages","Educational programming languages","High-level programming languages",...<class 'bs4.BeautifulSoup'>
Extracting information
We know from the first step inspecting the website that the paragraph of interest is the third child of the <div> tag with "class"="mw-parser-output".
Python is dynamically-typed and garbage-collected. It supports multiple programming paradigms, including structured (particularly, procedural), object-oriented and functional programming. Python is often described as a "batteries included" language due to its comprehensive standard library.[31]