

Pandas DataFrame | join method
Start your free 7-days trial now!
Pandas DataFrame.join(~) merges the source DataFrame with another Series or DataFrames.
The join(~) method is a wrapper around the merge(~) method, so if you want more control over the join process, consider using merge(~) instead.
Parameters
1. otherlink | Series or DataFrame or list of DataFrames
The other object to join with.
2. onlink | string or list | optional
The column or index level name of the source DataFrame to perform the join on. The index of the other will be used for the join. If you want to specify a non-index column to join on for other, use merge(~) instead, which has a right_on parameter.
3. howlink | string | optional
The type of join to perform:
Value | Description |
|---|---|
All rows from the source DataFrame will be present in the resulting DataFrame. This is the SQL equivalent of a left-join. | |
All rows from the right DataFrame will be present in the resulting DataFrame. This is the SQL equivalent of a right-join. | |
All rows from the source and right DataFrame will be present in the resulting DataFrame. This is the SQL equivalent of an outer-join. | |
All rows that have matching values in both the source and right DataFrame will be present in the resulting DataFrame. This is the SQL equivalent to inner-join. |
By default, how="left".
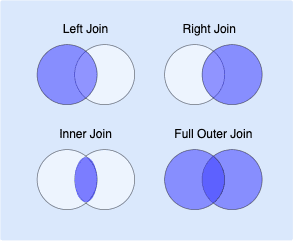
Here's the classic Venn Diagram illustrating the differences:
4. lsuffixlink | string | optional
The suffix to append to the overlapping label of the source DataFrame. This is only relevant if there are duplicate column labels in the result. By default, lsuffix="".
5. rsuffixlink | string | optional
The suffix to append to the overlapping label of other. This is only relevant if there are duplicate column labels in the result. By default, rsuffix="".
6. sortlink | boolean | optional
Whether or not to sort the rows based on the join key. By default, sort=False.
Return Value
A merged DataFrame.
Examples
Basic usage
Consider the following DataFrame about some products of a shop:
"bought_by": ["bob", "alex", "bob"]}, index=["A","B","C"])df_products
product bought_byA computer bobB smartphone alexC headphones bob
Here's a DataFrame about some customers of the shop:
agealex 10bob 20cathy 30
To perform a left-join on the bought_by column of df_products:
df_products.join(df_customers, on="bought_by") # how="left"
product bought_by ageA computer bob 20B smartphone alex 10C headphones bob 20
By default, the index of other will be used as the join key. If you want more flexibility as to which columns are used for the join, use the merge(~) method instead.
Comparison of different joins
Consider the following DataFrames about products and customers:
[df_products] | [df_customers] product bought_by | ageA computer bob | alex 10B smartphone alex | bob 20C headphones david | cathy 30
Left join
df_products.join(df_customers, on="bought_by", how="left")
product bought_by ageA computer bob 20.0B smartphone alex 10.0C headphones david NaN
Right join
df_products.join(df_customers, on="bought_by", how="right")
product bought_by ageB smartphone alex 10A computer bob 20NaN NaN cathy 30
Inner join
df_products.join(df_customers, on="bought_by", how="inner")
product bought_by ageA computer bob 20C headphones bob 20B smartphone alex 10
Outer join
df_products.join(df_customers, on="bought_by", how="outer")
product bought_by ageA computer bob 20C headphones bob 20B smartphone alex 10NaN NaN cathy 30
Specifying lsuffix and rsuffix
Suppose we wanted to join the following DataFrames:
product age bought_by | ageA computer 5 bob | alex 10B smartphone 6 alex | bob 20C headphones 7 bob | cathy 30
Notice how both DataFrames have the age column.
Due to this overlap in the naming, performing the join results in a ValueError:
df_products.join(df_customers, on="bought_by")
ValueError: columns overlap but no suffix specified: Index(['age'], dtype='object')
This error can be resolved by specifying lsuffix or rsuffix:
df_products.join(df_customers, on="bought_by", lsuffix="_product")
product age_product bought_by ageA computer 5 bob 10B smartphone 6 alex 10C headphones 7 bob 20
Note that lsuffix and rsuffix only take effect when there are duplicate column labels.
Specifying sort
Consider the same example as before:
[df_products] | [df_customers] product bought_by | ageA computer bob | alex 10B smartphone alex | bob 20C headphones bob | cathy 30
By default, sort=False, which means that the resulting DataFrame's rows are not sorted by the join key (bought_by):
df_products.join(df_customers, on="bought_by") # sort=False
product bought_by ageA computer bob 20B smartphone alex 10C headphones bob 20
Setting sort=True yields:
df_products.join(df_customers, on="bought_by", sort=True)
product bought_by ageB smartphone alex 10A computer bob 20C headphones bob 20