

Comprehensive guide on caching in PySpark
Start your free 7-days trial now!
Prerequisites
To follow along with this guide, you should know what RDDs, transformations and actions are. Please visit our comprehensive guide on RDD if you feel rusty!
What is caching in Spark?
The core data structure used in Spark is the resilient distributed dataset (RDD). There are two types of operations one can perform on a RDD: a transformation and an action. Most operations such as mapping and filtering are transformations. Whenever a transformation is applied to a RDD, a new RDD is made instead of mutating the original RDD directly:
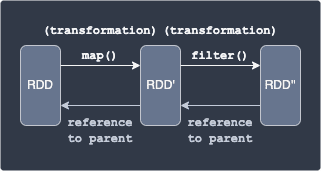
Here, applying the map transformation on the original RDD creates RDD', and then applying the filter transformation creates RDD''.
Now here is where caching comes into play. Suppose we wanted to apply a transformation on RDD'' multiple times. Without caching, RDD'' must be computed from scratch using RDD each time. This means that if we apply a transformation on RDD'' 10 times, then RDD'' must be generated 10 times from RDD. If we cache RDD'', then we no longer have to recompute RDD'', but instead reuse the RDD'' that exists in cache. In this way, caching can greatly speed up your computations and is therefore critical for optimizing your PySpark code.
How to perform caching in PySpark?
Caching a RDD or a DataFrame can be done by calling the RDD's or DataFrame's cache() method. The catch is that the cache() method is a transformation (lazy-execution) instead of an action. This means that even if you call cache() on a RDD or a DataFrame, Spark will not immediately cache the data. Spark will only cache the RDD by performing an action such as count():
# Cache will be created because count() is an action
Here, df.cache() returns the cached PySpark DataFrame.
We could also perform caching via the persist() method. The difference between count() and persist() is that count() stores the cache using the setting MEMORY_AND_DISK, whereas persist() allows you to specify storage levels other than MEMORY_AND_DISK. MEMORY_AND_DISK means that the cache will be stored in memory if possible, otherwise the cache will be stored in disk. Other storage levels include MEMORY_ONLY and DISK_ONLY.
Basic example of caching in PySpark
Consider the following PySpark DataFrame:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 30||Cathy| 40|+-----+---+
Let's print out the execution plan of the filter(~) operation that fetches rows where the age is not 20:
== Physical Plan ==*(1) Filter (isnotnull(age#6003L) AND NOT (age#6003L = 20))+- *(1) Scan ExistingRDD[name#6002,age#6003L]
Here note the following:
the
explain()method prints out the physical plan, which you can interpret as the actual execution planthe executed plan is often read from bottom to top
we see that PySpark first scans the DataFrame (
Scan ExistingRDD). RDD is shown here instead of DataFrame because, remember, DataFrames are implemented as RDDs under the hood.while scanning, the filtering (
isnotnull(age) AND NOT (age=20)) is applied.
Let us now cache the PySpark DataFrame returned by the filter(~) method using cache():
Here, the count() method is an action, which means that the PySpark DataFrame returned by filter(~) will be cached.
Let's call filter(~) again and print the physical plan:
== Physical Plan ==InMemoryTableScan [name#6002, age#6003L] +- InMemoryRelation [name#6002, age#6003L], StorageLevel(disk, memory, deserialized, 1 replicas) +- *(1) Filter (isnotnull(age#6003L) AND NOT (age#6003L = 20)) +- *(1) Scan ExistingRDD[name#6002,age#6003L]
The physical plan is now different from when we called filter(~) before caching. We see two new operations: InMemoryTableScan and InMemoryRelation. Behind the scenes, the cache manager checks whether a DataFrame resulting from the same computation exists in cache. In this case, we have cached the resulting DataFrame from filter('age!=20') previously via cache() followed by an action (count()), so the cache manager uses this cached DataFrame instead of recomputing filter('age!=20'). The InMemoryTableScan and InMemoryRelation we see in the physical plan indicate that we are working with the cached version of the DataFrame.
Using the cached object explicitly
The methods cache() and persist() return a cached version of the RDD or DataFrame. As we have seen in the above example, we can cache RDDs or DataFrames without explicitly using the returned cached object:
It is better practise to use the cached object returned by cache() like so:
The advantage of this is that calling methods like df_cached.count() clearly indicates that we are using a cached DataFrame.
Confirming cache via Spark UI
We can also confirm the caching behaviour via the Spark UI by clicking on the Stages tab:
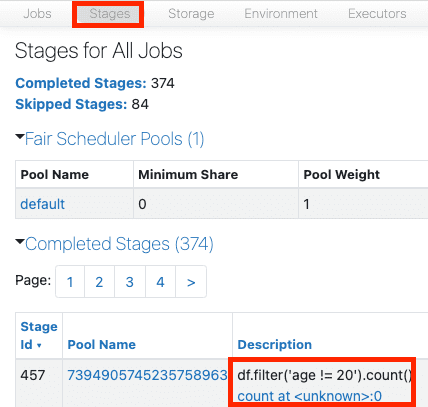
Click on the link provided in the Description column. This should open up a graph that shows the operations performed under the hood:
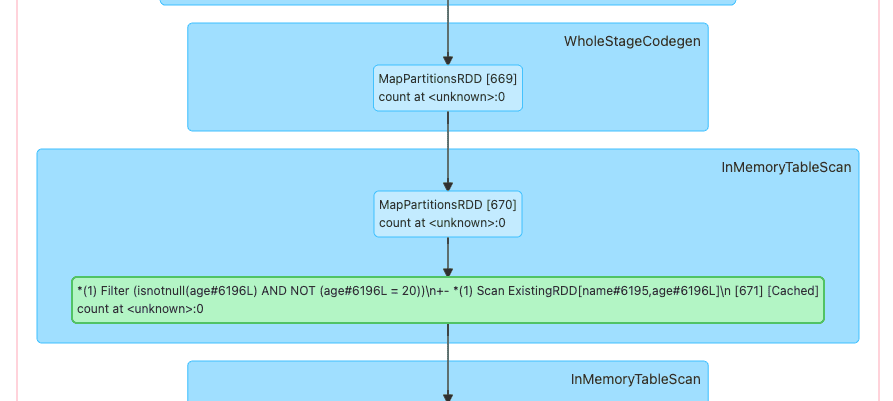
You should see a green box in the middle, which means that this specific operation was not computed thanks to a presence of a cache.
Note that if you are using Databricks, then click on View in the output cell:
This should open up the Spark UI and show you the same graph as above.
We could also see the stored caches on the Storage tab:
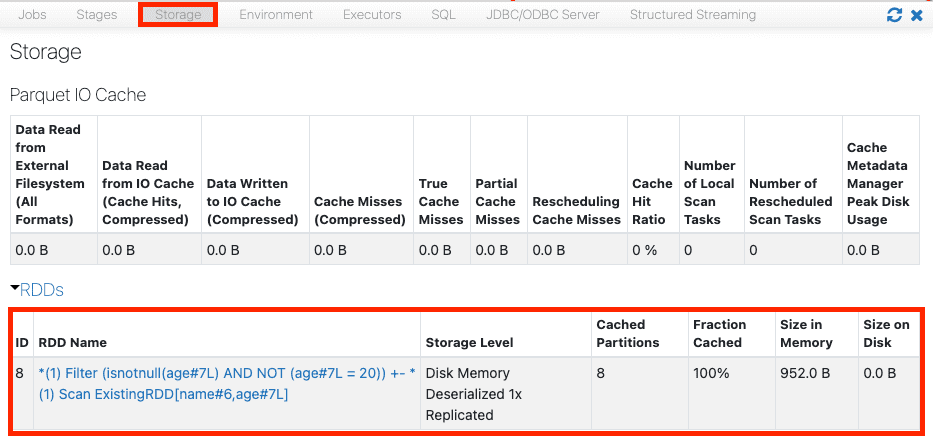
We can see that all the partitions of the RDD (8 in this case) resulting from the operation filter.(age!=20) is stored in memory cache as opposed to disk cache. This is because the storage level of the cache() method is set to MEMORY_AND_DISK by default, which means to store the cache in disk only if the cache does not fit in memory.
Clearing existing cache
To clear (evict) all the cache, call the following:
spark.catalog.clearCache()
To clear the cache of a specific RDD or DataFrame, call the unpersist() method:
# Trigger an action to persist cachedf_cached.count()# Delete the cachedf_cached.unpersist()
It is good practise to clear cache because if space starts running out, Spark will begin removing cache using the LRU (least recently used) policy. It is generally better to not rely on automatic deletion because it may delete cache that is vital for your PySpark application.
Things to consider when caching
Cache computed data that is used frequently
Caching is recommended when you use the same computed RDD or DataFrame multiple times. Do remember that computing RDDs is generally very fast, so you may consider caching only when your PySpark program is too slow for your needs.
Cache minimally
We should cache frugally because caching consumes memory, and memory is needed for the worker nodes to perform their tasks. If we do decide to cache, make sure that you're only caching the part of data that you will reuse multiple times. For instance, if we are going to frequently perform some computation on column A only, then it makes sense to cache column A instead of the entire DataFrame. Another example is if you have two queries where one involves columns A and B, and the other involves columns B and C, then it may be a good idea to cache columns A, B and C instead of caching columns (A and B) and columns (B and C) which will store column B in cache redundantly.