

File system in Databricks
Start your free 7-days trial now!
What is Databricks filesystem?
Every Azure Databricks workspace has a mounted filesystem called DBFS (Databricks file system). Under the hood, DBFS is actually a scalable object storage but what's great about it is that we can use Unix-like commands (e.g. ls) to interact with it.
Besides the DBFS, we also have access to the file system of the driver node. This guide will go through both types of file systems and how they are related.
File system in the driver node
Using magic command
To see the files in the driver node, use the %sh magic command:
%sh ls
azureconfeventlogshadoop_accessed_config.lstlogspreload_class.lst
Note that the output is misleading because some directories such as /dbfs and /Workspace are not listed here. We will go into more details about these hidden directories later.
Writing to and reading from driver node's filesystem
The file system accessed by the os library will also point to the file system of the driver node:
import osos.listdir()
['azure', 'preload_class.lst', 'hadoop_accessed_config.lst', 'conf', 'eventlogs', 'logs']
Except when using PySpark, the files that we write ends up in the file system of the driver's node. For instance, let's write a dictionary as a JSON file like so:
import jsonwith open("./my_file.json", "w") as file: json.dump({"A":1}, file)
The written JSON file can be found in the file system of the driver's node:
%sh ls
azureconf...my_file.json...
Again, except when using PySpark functions, files are usually read from the driver node:
with open("./my_file.json", "r") as file: my_json = json.load(file) print(my_json)
{'A': 1}
File system of DBFS
Using magic command
To access the files in DBFS, use the %fs magic command:
%fs ls
path name size modificationTime1 dbfs:/FileStore/ FileStore/ 0 02 dbfs:/databricks-datasets/ databricks-datasets/ 0 03 dbfs:/databricks-results/ databricks-results/ 0 04 dbfs:/tmp/ tmp/ 0 05 dbfs:/user/ user/ 0 0
Note that the size column is misleading because it looks as though the folders are empty. However, size is always equal to zero for folders (but not for files as we will see later).
Default folders in DBFS root
Let's go through the nature of the default 5 folders:
Folder | Description |
|---|---|
| Stores files uploaded to Databricks. |
| Open-source datasets for exploration. |
| Stores results downloaded via the |
| Folder for temporary folders - this is managed by you and not Databricks, that is, Databricks will not delete the content of this folder. |
| Stores uploaded datasets that are registered as Databricks tables. |
Let's now take a look at what's inside the databricks-datasets/ folder:
%fs ls databricks-datasets/
path name size modificationTime1 dbfs:/databricks-datasets/COVID/ COVID/ 0 02 dbfs:/databricks-datasets/README.md README.md 976 15324682530003 dbfs:/databricks-datasets/Rdatasets/ Rdatasets/ 0 04 dbfs:/databricks-datasets/SPARK_README.md path 3359 14550434900005 dbfs:/databricks-datasets/adult/ adult/ 0 06 dbfs:/databricks-datasets/airlines/ airlines/ 0 0
We see that the databricks-datasets directory contains some sample datasets that we can use for our own exploration!
Using dbutils command
We could also use the dbutils method like so:
dbutils.fs.ls("/databricks-datasets")
[FileInfo(path='dbfs:/databricks-datasets/COVID/', name='COVID/', size=0, modificationTime=0), FileInfo(path='dbfs:/databricks-datasets/README.md', name='README.md', size=976, modificationTime=1532468253000), FileInfo(path='dbfs:/databricks-datasets/Rdatasets/', name='Rdatasets/', size=0, modificationTime=0), FileInfo(path='dbfs:/databricks-datasets/SPARK_README.md', name='SPARK_README.md', size=3359, modificationTime=1455043490000), FileInfo(path='dbfs:/databricks-datasets/adult/', name='adult/', size=0, modificationTime=0), ...
Writing PySpark DataFrame into DBFS
By default, PySpark DataFrames are written to and read from DBFS. For instance, suppose we write a PySpark DataFrame as a CSV file like so:
df.write.csv("my_data.csv", header=True)
Our CSV file can be found in the DBFS root folder:
%fs ls
path name size modificationTime1 dbfs:/FileStore/ FileStore/ 0 16887922390002 dbfs:/Volume/ Volume/ 0 03 dbfs:/Volumes/ Volumes/ 0 04 dbfs:/databricks-datasets/ databricks-datasets/ 0 05 dbfs:/databricks-results/ databricks-results/ 0 06 dbfs:/my_data.csv/ my_data.csv/ 0 1689247799000
Here, the my_data.csv has a size of 0 because it is a directory. The actual CSV file containing our data is inside this directory.
Reading PySpark DataFrame from DBFS
To read our my_data.csv from DBFS as a PySpark DataFrame:
df = spark.read.format("csv") \ .option("header", True) \ .option("inferSchema", "true") \ .load("/my_data.csv")
+----+---+|name|age|+----+---+|Alex| 20|| Bob| 30|+----+---+
Moving files between driver node and DBFS
Copying files from driver node to DBFS
Let's first write a text file to the driver node like so:
with open("sample.txt", "w") as file: file.write("Hello world!")
To copy this file from the driver node to DBFS:
dbutils.fs.cp("file:///databricks/driver/sample.txt", "dbfs:/my_sample.txt")
To confirm that our text file now exists in DBFS:
%fs ls
path name size modificationTime1 dbfs:/FileStore/ FileStore/ 0 02 dbfs:/Volumes/ Volumes/ 0 03 dbfs:/databricks-datasets/ databricks-datasets/ 0 04 dbfs:/databricks-results/ databricks-results/ 0 05 dbfs:/my_sample.txt my_sample.txt 12 1688792423000
Copying files from DBFS to driver node
Let's start by uploading a text file to DBFS. Navigate to a notebook, and click on the Upload data to DBFS button:
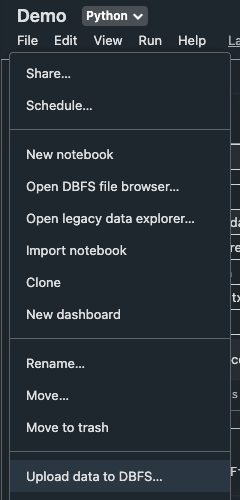
By default, all files that we upload through this way will be stored under /FileStore in DBFS. I will upload a text file called hello_world.txt like so:
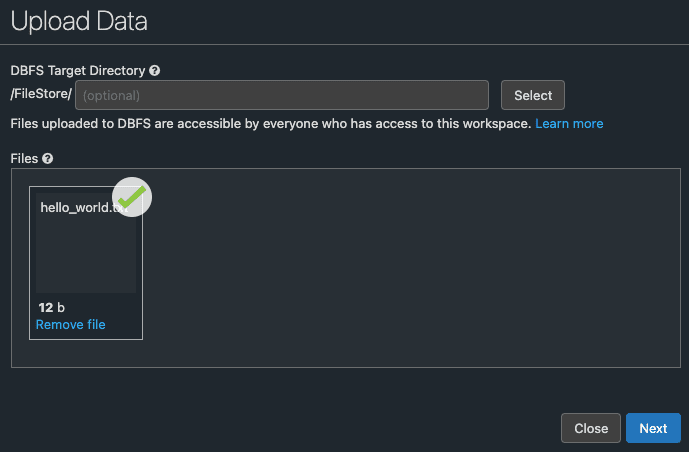
Clicking on the Next button gives:
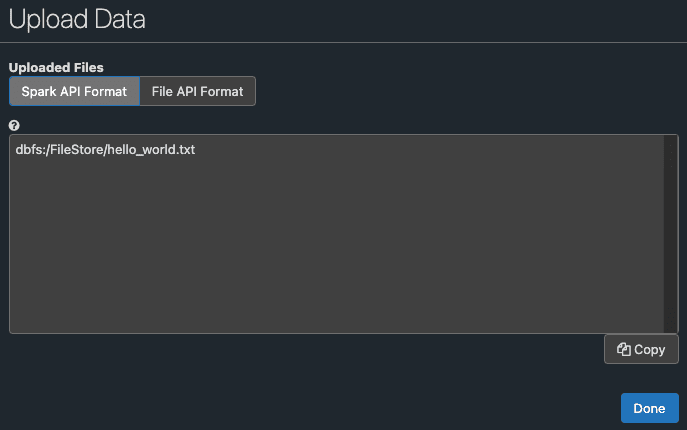
For reference later, the File API format is:
/dbfs/FileStore/hello_world.txt
Let's now check that the text file exists in DBFS:
%fs ls dbfs:/FileStore/
path name size modificationTime1 dbfs:/FileStore/hello_world.txt hello_world.txt 12 1688831344000
Let's now use the dbutils method to copy the text file from DBFS to the driver node:
dbutils.fs.cp("dbfs:/FileStore/hello_world.txt", "file:///databricks/driver/hello_world.txt")
True
Let's check that the file is now available in the file system of the driver node:
%sh ls
azure...hello_world.txt...
Finally, we can read the content of the text file in our notebook:
with open("hello_world.txt", "r") as file: content = file.read() print(content)
Hello world
Accessing files in DBFS directly in the driver node file system
In the previous section, we have copied files from the driver node to DBFS. However, DBFS is mounted in the driver node under the /dbfs directory:
%sh ls /dbfs
FileStoreVolumesdatabricksdatabricks-datasetsdatabricks-resultsuser
Here, the directories in the output are what we see when we run %fs ls.
Therefore, instead of copying the text file from DBFS to the driver node, we can directly access the text file at /dbfs/FileStore/hello_world.txt - this is exactly the File API format of the text file that we noted earlier:
with open("/dbfs/FileStore/hello_world.txt", "r") as file: content = file.read() print(content)
Hello world
Workspace files
Workspace files are the files that you can create and store in your Databricks workspace. Workspace files can be notebooks, Python scripts, SQL scripts, text files, or any other type of file that you want to work with in Databricks.
These files are stored within the workspace, which provides a hierarchical organization structure to manage your files and folders. You can create, edit, and delete workspace files directly within the Databricks workspace UI or through the Databricks CLI or APIs.
Uploading workspace files using Databricks UI
As an example, let's upload a text file called hello_world.txt via Databricks UI in our dedicated folder below:
/Workspace/Users/support@skytowner.com
In the Workspace tab, right-click on our dedicated workspace directory and click on Import like so:
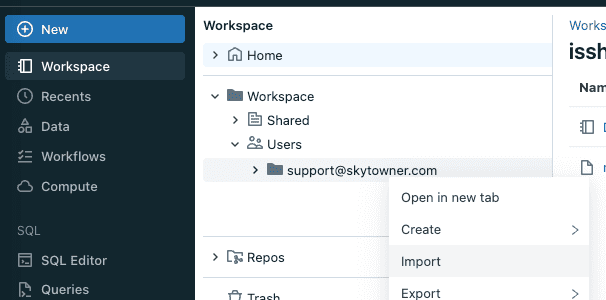
Behind the scenes, Databricks will upload this file into the driver node's file system instead of DBFS.
After uploading our hello_world.txt file, we should have the following files in our account workspace:
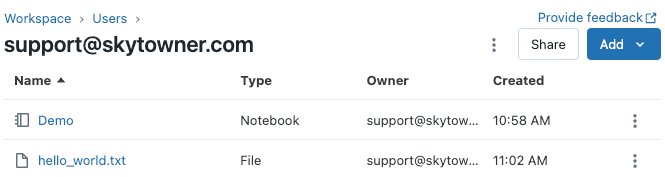
Here, we will use our Demo notebook to write some Python code that reads the hello_world.txt file.
Accessing workspace files programatically
In our Demo notebook, we can check for the existence of our new file by:
%sh ls /Workspace/Users/support@skytowner.com
Demohello_world.txt
Here, we are using %sh instead of %fs because the workspace files are located in the driver node's file system.
We can also programatically access the text file like so:
with open("/Workspace/Users/support@skytowner.com/hello_world.txt", "r") as file: content = file.read() print(content)
Hello world
Mounting object storage to DBFS
Mounting Azure blob storage
Let's mount our Azure blob storage to DBFS such that we can access our storage directly through DBFS. To do so, use the dbutils.fs.mount() method:
storage_account = "demostorageskytowner"container = "democontainer"access_key = "*****"
dbutils.fs.mount( source = f"wasbs://{container}@{storage_account}.blob.core.windows.net", mount_point = "/mnt/my_demo_storage", extra_configs = { f"fs.azure.account.key.{storage_account}.blob.core.windows.net": access_key })
True
Here, the access_key can be obtained in the Azure portal:
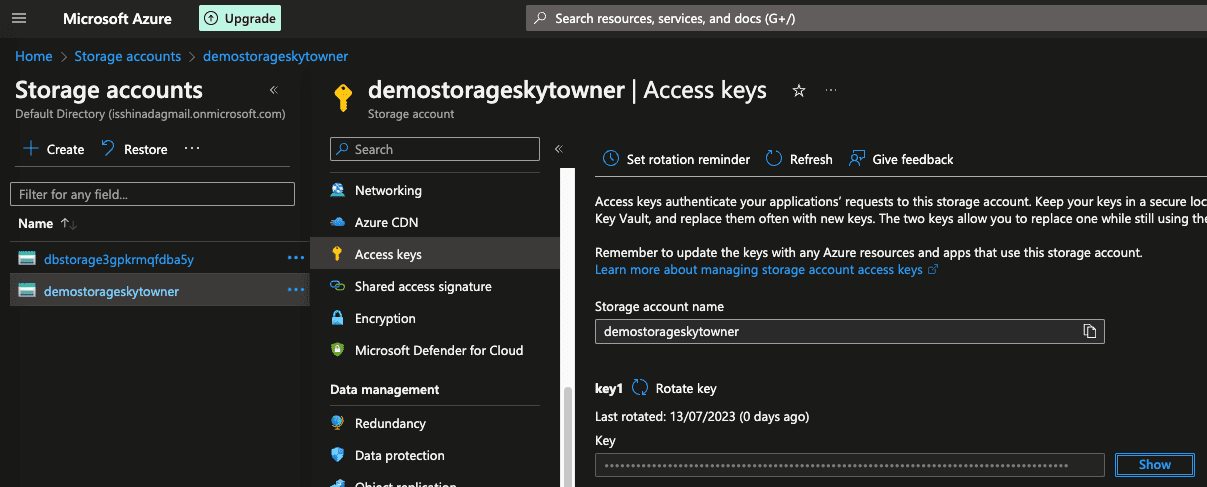
We can now access all the files in our blob storage using DBFS like so:
%fs ls /mnt/
path name size modificationTime1 dbfs:/mnt/my_demo_storage/ my_demo_storage/ 0 0
Let's have a look at what's inside our blob storage:
%fs ls /mnt/my_demo_storage/
path name size modificationTime1 dbfs:/mnt/my_demo_storage/hello_world.txt hello_world.txt 12 1689250809000
Reading files from mounted storage
Recall that the DBFS is mounted on the driver node as /dbfs, which means we can directly access the files in our blob storage like so:
with open("/dbfs/mnt/my_demo_storage/hello_world.txt", "r") as file: content = file.read() print(content)
Hello world
Writing files to mounted storage
Let's now write a text file to the mounted storage:
with open("/dbfs/mnt/my_demo_storage/bye_world.txt", "w") as file: file.write("Bye world!")
Let's check that the new file has been written into the mounted storage:
%fs ls /mnt/my_demo_storage/
path name size modificationTime1 dbfs:/mnt/my_demo_storage/bye_world.txt bye_world.txt 10 16892533010002 dbfs:/mnt/my_demo_storage/hello_world.txt hello_world.txt 12 1689250809000
We can also check the Azure blob UI dashboard to see that this text file is present:

Unmounting storage
To unmount the storage:
dbutils.fs.unmount("/mnt/my_demo_storage")
/mnt/my_demo_storage has been unmounted.