

PySpark DataFrame | join method
Start your free 7-days trial now!
PySpark DataFrame's join(~) method joins two DataFrames using the given join method.
Parameters
1. other | DataFrame
The other PySpark DataFrame with which to join.
2. on | string or list or Column | optional
The columns to perform the join on.
3. how | string | optional
By default, how="inner". See examples below for the type of joins implemented.
Return Value
A PySpark DataFrame (pyspark.sql.dataframe.DataFrame).
Examples
Performing inner, left and right joins
Consider the following PySpark DataFrames:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 24||Cathy| 22|+-----+---+
The other PySpark DataFrame:
+----+------+|name|salary|+----+------+|Alex| 250|| Bob| 200||Doge| 100|+----+------+
Inner join
For inner join, all rows that have matching values in both the source and right DataFrame will be present in the resulting DataFrame:
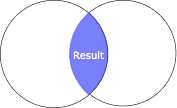
+----+---+------+|name|age|salary|+----+---+------+|Alex| 20| 250|| Bob| 24| 200|+----+---+------+
Left join and left-outer join
For left join (or left-outer join), all rows in the left DataFrame and matching rows in the right DataFrame will be present in the resulting DataFrame:
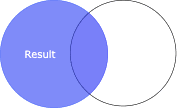
+-----+---+------+| name|age|salary|+-----+---+------+| Alex| 20| 250|| Bob| 24| 200||Cathy| 22| null|+-----+---+------+
Right join and right-outer join
For right (right-outer) join, all rows in the right DataFrame and matching rows in the left DataFrame will be present in the resulting DataFrame:
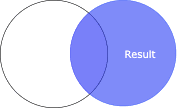
+----+----+------+|name| age|salary|+----+----+------+|Alex| 20| 250|| Bob| 24| 200||Doge|null| 100|+----+----+------+
Performing outer join
Consider the same PySpark DataFrames as before:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 24||Cathy| 22|+-----+---+
This is the other PySpark DataFrame:
+----+------+|name|salary|+----+------+|Alex| 250|| Bob| 200||Doge| 100|+----+------+
For outer join, both the left and right DataFrames will be present:

+-----+----+------+| name| age|salary|+-----+----+------+| Alex| 20| 250|| Bob| 24| 200||Cathy| 22| null|| Doge|null| 100|+-----+----+------+
Performing left-anti and left-semi joins
Consider the same PySpark DataFrames as before:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 24||Cathy| 22|+-----+---+
This is the other DataFrame:
+----+------+|name|salary|+----+------+|Alex| 250|| Bob| 200||Doge| 100|+----+------+
Left anti-join
For left anti-join, all rows in the left DataFrame that are not present in the right DataFrame will be in the resulting DataFrame:

+-----+---+| name|age|+-----+---+|Cathy| 22|+-----+---+
Left semi-join
Left semi-join is the opposite of left-anti join, that is, all rows in the left DataFrame that are present in the right DataFrame will be in the resulting DataFrame:
+----+---+|name|age|+----+---+|Alex| 20|| Bob| 24|+----+---+
Performing join on different column names
Up to now, we have specified the join key using the on parameter. Let's now consider the case when the join keys have different labels. Suppose one DataFrame is as follows:
+-----+---+| name|age|+-----+---+| Alex| 20|| Bob| 24||Cathy| 22|+-----+---+
Suppose the other DataFrame is as follows:
+----+------+|NAME|salary|+----+------+|Alex| 250|| Bob| 200||Doge| 100|+----+------+
We can join using name of df1 and NAME of df2 like so:
cond = [df1["name"] == df2["NAME"]]
+----+---+----+------+|name|age|NAME|salary|+----+---+----+------+|Alex| 20|Alex| 250|| Bob| 24| Bob| 200|+----+---+----+------+
Here, we can supply multiple join keys since on accepts a list.